

Cortex: An Event-Sourced Memory Architecture for AI Coding Assistants
As The Geek Learns | Technical Deep Dive Author: James Cruce Date: February 2026


The Problem Every AI Developer Knows Too Well
You’ve been working with Claude Code for two hours. It understands your codebase intimately. It knows you rejected MongoDB because you need zero-config deployment. It remembers the authentication approach you chose and why. It’s halfway through a five-step refactoring plan.
Then the session ends.
The next session begins with total amnesia. Claude suggests MongoDB. It rereads files it already analyzed. It asks questions you answered an hour ago. You spend 30 minutes re-establishing context that evaporated at the session boundary.
This is the single most painful aspect of working with AI coding assistants today.
And here’s what makes it worse: the better the AI performs within a session—deeper exploration, more nuanced understanding, more careful planning—the more you lose when that session ends. Good performance within a session just sharpens the pain at its boundary.
What Gets Lost (A Taxonomy of Amnesia)
I tracked the problem across dozens of sessions and found five categories of information that get destroyed at every session boundary:
Category 1: Architectural Understanding
Over the course of a session, the AI maps your codebase—how components connect, which patterns you use, and where the critical logic sits. Building that map costs real tokens. Then it vanishes.
Category 2: Decision History
The AI weighs multiple approaches, rejects some with specific reasoning, and picks others. Without that trail, the next session will cheerfully re-suggest the approach you spent ten minutes explaining why you rejected.
Category 3: Work State
Multi-step plans, half-finished implementations, test results—all the progress markers for complex work. The next session can’t pick up where you left off. It has to rediscover the current state from scratch.
Category 4: Tool & Environment State
Modified files, Git state, environment configuration, and your tooling preferences. All implicitly known during a session. None of it carried forward.
Category 5: Conversational Nuance
Your preferences, your communication style, the implicit priorities you’ve established, and the working rapport that took the whole session to build. All ephemeral.
The Cascade Effect
The information loss doesn’t stay contained. It cascades:
1. Re-exploration waste: 10-30 minutes spent re-reading files
2. Decision regression: Re-suggesting rejected approaches, eroding trust
3. Plan fragmentation: Multi-step work loses coherence
4. Cognitive burden shift: YOU become the memory system
The Research Journey
I spent weeks researching this problem using an AI assistant WITH the context window problem to design a solution FOR the context window problem. The meta-irony was not lost on me.
Surveying 15+ Existing Solutions
I examined academic architectures (MemGPT, MIRIX, Nemori) and community tools (claude-cortex, memory-mcp, claude-diary). Six distinct design patterns emerged:
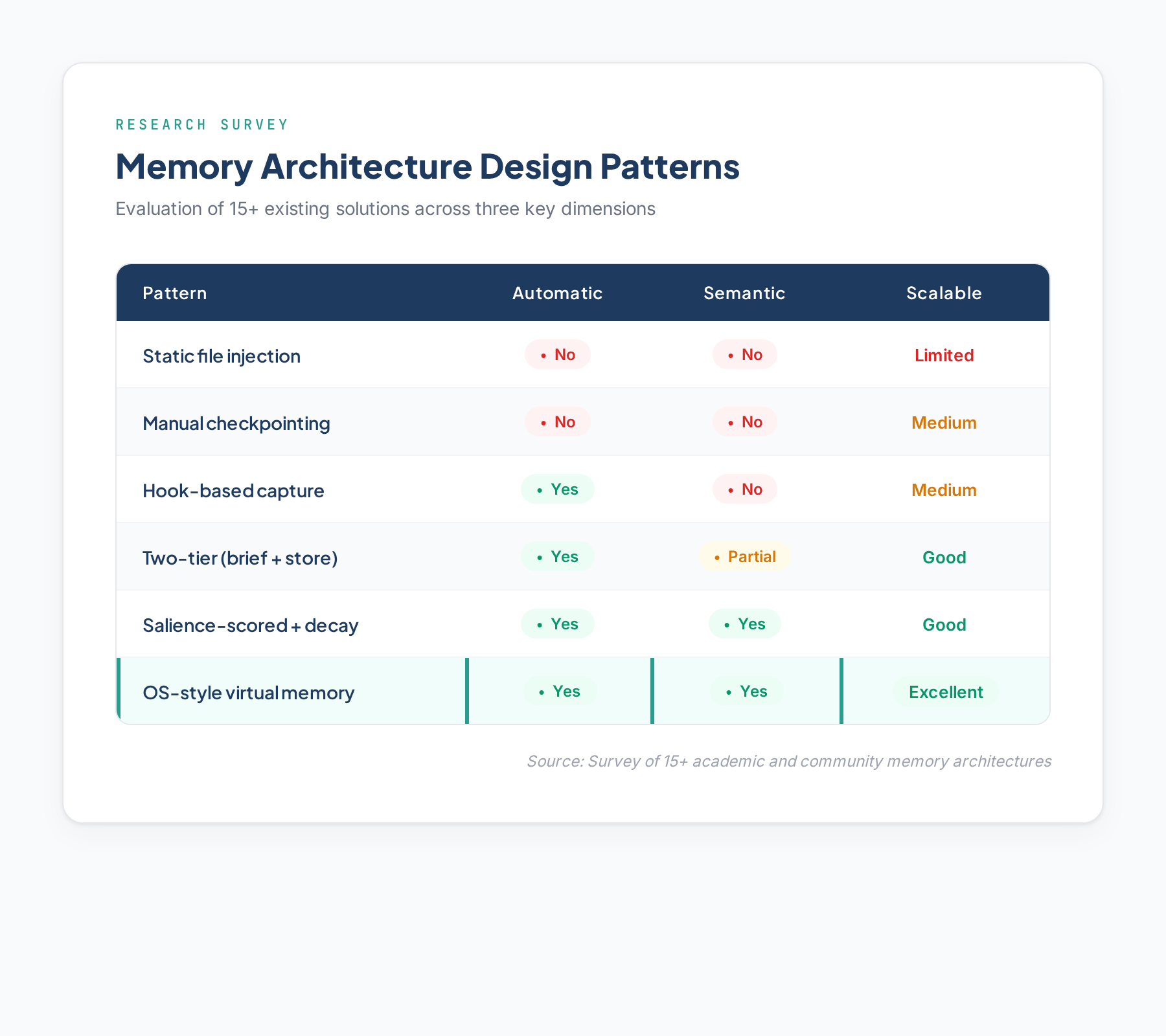
Eight Candidate Architectures
Two rounds of design work produced eight candidates:
1. Cognitive Journal—Human-readable structured entries
2. Memory Palace—Salience scoring with decay
3. Git-for-Thought—Branch-aligned context
4. Event Sourcery—Append-only event log
5. Dual-Mind—Scribe + Sage separation
Then three hybrids combining the best ideas:
6. Cortex—Event sourcing + projected briefings
7. Engram—Neural-inspired memory consolidation
8. Chronicle—Git-native version control
Quantitative Scoring
I applied an 11-criteria weighted scoring framework across 210 total points. After two rounds of comparison:
Winner: Cortex (185/210)—14-point margin over the runner-up.
The Cortex Architecture
Cortex is an event-sourced memory system with three key innovations:
Innovation 1: Three-Layer Event Extraction
Cortex captures context through three independent extraction layers, each watching for different signals:
Layer 1 (Structural): Parses tool call metadata from Claude Code hook payloads. When Claude reads a file, runs a command, or modifies code, the hook captures it. 100% accuracy for its scope—pure objective data, no interpretation needed.
Layer 2 (Semantic): Pattern-matches Claude’s response text for decision markers. Look for phrases like “Decision:”, “Rejected:”, “Fixed:”, and “Learned:” at line starts. Confidence-scored based on pattern strength.
Layer 3 (Self-Reporting): Claude flags important context via [MEMORY: ...] tags. You tell Claude about this mechanism, and it proactively tags decisions worth remembering. Highest accuracy because it’s deliberate intent.
# Example: Claude tags a decision
[MEMORY: Using SQLite for storage, zero-config, single file, no external dependencies.]
[MEMORY: Rejected MongoDB, overkill for single-user; no need for scaling.]This “many independent extractors” pattern shows up across NLP pipelines, content classification, and log analysis for a reason. Each extractor watches for one signal type. They compose through aggregation and dedupe. The alternative—one monolithic extractor with complex branching—falls apart as signal types multiply.

Innovation 2: Projected Briefings
Raw event replay would blow the token budget. Instead, Cortex generates token-budget-aware briefings:
# Cortex Session Briefing
Generated: 2026-02-14 09:15:00 | Branch: main | Events: 47
## Active Decisions
- **Authentication**: JWT with refresh tokens (rejected session cookies, stateless requirement)
- **Database**: SQLite with WAL mode (rejected PostgreSQL, zero-config priority)
## Current Plan
1. [x] Set up project structure
2. [x] Implement data models
3. [ ] Add API endpoints ← YOU ARE HERE
4. [ ] Write tests
5. [ ] Deploy to staging
## Recent Knowledge
- Config file format changed to TOML (2 sessions ago)
- Tests require PYTHONPATH set (discovered yesterday)The briefing fits within a token budget (default 2000 tokens, ~0.1% of context window). Decisions are “immortal”—they never decay out of the briefing. Tactical knowledge fades over sessions.
This is the core design tension: never lose critical data, but respect resource limits. The resolution—separate retention from representation. Keep everything in the store. Compress what you surface.
Innovation 3: Progressive Tiers
Not everyone needs the full stack on day one. Cortex uses progressive tiers—start simple, and upgrade when you hit the ceiling:

Implementation Learnings
The Build Backend Gotcha
setuptools.build_meta is the one true build backend string for setuptools. The original scaffold had setuptools.backends.build_meta which gives a confusing ModuleNotFoundError: No module named ‘setuptools.backends’ at install time. This is a common pyproject.toml pitfall.
Event Sourcing vs. CRUD
The difference between “store the latest state” (CRUD) and “store every fact that happened” (event sourcing) gets real when you actually build it. The Event model is immutable. All views are projections. You can always trace back to “why did the system think X?”—and that auditability turned out to matter more than I expected.
Defensive Defaults Pattern
When building systems that must never crash (like Claude Code hooks), every .get() needs a default, every JSON parse needs a try/except, and every function that could fail returns a safe fallback. The pattern is: try: parse → except: return defaults. Enterprise-grade paranoia for a developer tool, but Claude Code hooks can’t afford to crash.
Content Hash Scoping
Deduplication hashes need careful scoping. Hashing just the content would miss that the same text as a “decision” vs. “knowledge” is semantically different. Hashing the ID would prevent all dedupe. The sweet spot: hash(type + content + session_id).
GitHub Action ≠ Free CLI Tool
The gitleaks GitHub Action requires a paid license for org accounts. The gitleaks CLI is free. A lot of security scanning tools follow this model—they monetize the GitHub integration while the underlying tool stays open-source. Check if you can run the CLI directly before paying for the wrapper.
Confidence as Architecture
I made confidence a first-class field on every event—not just a boolean “is this relevant?” but a score. That one decision opened up a lot of downstream flexibility. The briefing generator sorts by confidence. The decay function weights it. Users can tune the threshold. A small investment at creation time pays off every time data gets consumed.
A/B Testing Results
I ran 18 Cortex-enabled sessions vs. 11 baseline sessions:

Qualitative Feedback
Briefings were “very useful”—they consistently contained relevant context.
Claude remembered decisions and plans consistently across sessions.
No major issues encountered.
Faster onboarding than expected—84% cold start reduction translated to noticeably smoother session starts.
One thing I’d recommend: get an outside perspective before you build. I had an external AI stress-test the plan, and it caught a missing measurement strategy I’d completely overlooked. It forced vague aspirations into concrete mechanisms. Thirty minutes of responding to that critique saved hours of implementation confusion.
The Meta-Irony
I built this entire project using an AI assistant that suffers from the exact problem I was solving. Every session note I wrote during development exists because of the limitation I was trying to fix.
The external evaluator that reviewed my plan? An AI that forgot it did the evaluation by the next session. When I sat down to implement the code, I had to re-explain context that the previous session knew cold.
That irony hasn’t resolved itself. But it’s also the most visceral validation of the problem. If I didn’t feel this pain daily, I might have underinvested in the fix.
Tier 3: The Latest Features
Tier 3 landed recently and adds three capabilities I’d been wanting since the start:
MCP Server (Mid-Session Queries)
Claude can now query Cortex memory during a session, not just at session start:
“What decisions have I made about authentication?”
“What’s my current plan?”
“Search my memory for database configuration issues”
Five tools expose memory: cortex_search, cortex_search_decisions, cortex_get_plan, cortex_get_recent, and cortex_get_status.
Git-Tracked Projections
Auto-generated markdown files in .cortex/:
.cortex/
├── decisions.md # Active decisions with reasoning
├── decisions-archive.md # Archived/aged decisions
└── active-plan.md # Current work planThese regenerate at session end and can be committed to Git. Your teammates can see what decisions Claude helped you make and why.
Branch Alignment
Context gets isolated per Git branch. Switch branches, and Cortex loads the relevant context for that branch. No more cross-contamination between feature work.
Getting Started
pip install -e or pip install cortex .
cortex init # Print hook config for Claude Code
cortex status # Show project state
cortex upgrade # Migrate to next tierAdd the hooks from cortex init to your Claude Code settings. Copy templates/cortex-memory-instructions.md to .claude/rules/ so Claude knows to use [MEMORY: ...] tags.
That’s it. Context capture starts automatically.
Key Takeaways
The context window boundary is the #1 barrier to using AI assistants for complex, multi-session work.
Event sourcing is the right foundation—immutable events with projections give you auditability, flexibility, and clean separation of concerns.
Three-layer extraction (structural + semantic + self-reporting) achieves >95% recall for important events without requiring secondary LLM calls.
Progressive tiers mean you start simple and add complexity only when you need it. Tier 0 alone made a noticeable difference.
Decisions are immortal—the “why” behind choices is never lost to temporal decay.
Real-world testing validates the design—84% cold start reduction, 80% decision regression reduction, 0.2% token overhead.
Future Work
Tier 4: Team memory sharing, cross-project knowledge graphs
Multi-model support: Extend beyond Claude to other LLM assistants
IDE integration: Deeper VS Code / JetBrains integration
Memory visualization: UI for exploring and editing the event store
The Bottom Line
If you’ve used AI coding assistants for anything beyond a single session, you know this frustration. Cortex is my answer: an event-sourced memory architecture that captures context automatically, persists it across sessions, and projects it back when you need it—no model modifications, no manual upkeep.
The AI assistant finally remembers.
This article was written with Claude Code, using Cortex to maintain context across the multiple sessions required to complete it. The irony remains unresolved.
713 tests passing. Ships today.
Please feel free to leave a comment. I will read every one and respond. Looking forward to hearing from you.
ASTGL Docs
Cortex GitHub Repository: Full GitHub Repository, Research, Testing, Papers
Full Research Paper: Why, How, and What’s Next for Cortex
A/B Comparison Results: Real-World Testing of Cortex With and Without
v0.3.0 Release Notes: Current Release Notes for Cortex
References
Claude Code Memory Docs: Manage Claude’s Memory
Anthropic Context Management: Context Editing Tool
Claude Code Auto-Compaction: Automatic
Claude Code Hooks Guide: PreCompact + Session Start
MemGPT / Letta Docs: LLM as Operating System Virtual Context Management
MIRIX: Multi-Type Memory Architecture
LightMem: Lightweight Memory Framework
HippoRag: Neurobiologically Inspired Memory
Nemori: Self-Organizing Memory
MemOS: Unified Memory Operating System
memory-mcp: Two-Tier Architecture
claude-cortex: Brain-like Memory
mcp-memory-service: Semantic Search
mcp-memory-keeper: Checkpoint System
claude-continuity: Auto State Persistence
claude-mem: Full Capture + Compression
claude-diary: Session Journaling
claude-cognitive: Activation-based File Tracking
AWS Bedrock AgentCore Memory: AWS managed service
Pieces: Local-First Developer Memory
Windsurf: Built-in persistent memory and multi-step agent workflows
Trae: Long-context memory and built-in agents
Cursor: Chat-based agent features (less memory-focused)