

Nightshift: I Went to Sleep and My Mac Ran 118 Experiments
What I learned about disciplined iteration from Karpathy's autoresearch loop running overnight on an M3 Ultra.

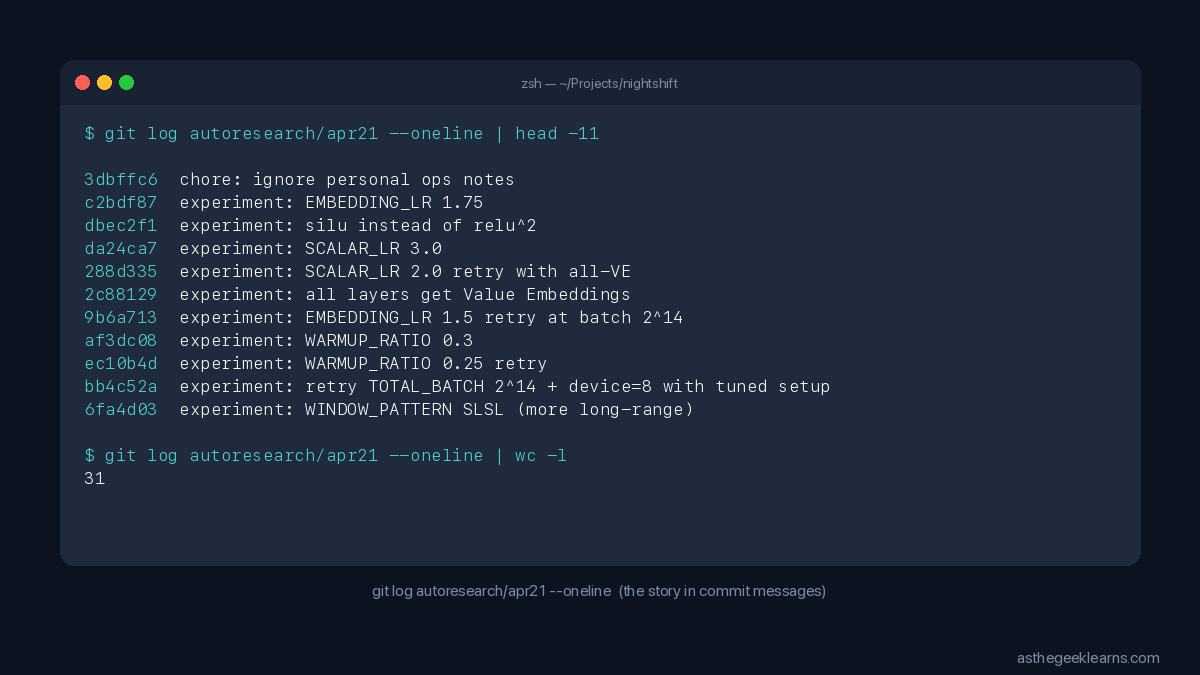
I went to sleep. My Mac ran 118 experiments. When I woke up, a small GPT had trained itself from `val_bpb` 1.563 down to 1.289, beating every documented Apple Silicon overnight run in the project's public README. I wrote no code overnight. I just left a Claude Code session running against a markdown file named `program.md`, and the agent did the rest.
This is the first morning I've ever genuinely understood why people talk about AI agents with something other than skepticism.

What autoresearch is
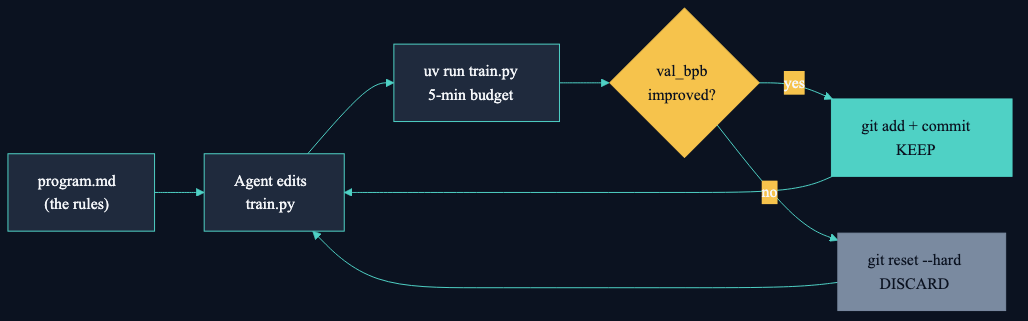
The idea, which is Karpathy's not mine, goes like this. You give an AI agent a real-but-small LLM training setup. One Python file (`train.py`) contains the model, optimizer, and training loop. A second file (`prepare.py`) contains the data pipeline and evaluation, and the agent isn't allowed to touch it. A third file (`program.md`) is a plain markdown document telling the agent what the experiment rules are.
The agent edits `train.py`, runs a training experiment with a fixed 5-minute wall-clock budget, checks `val_bpb` (validation bits per byte, a loss metric where lower is better), and either keeps the change with a git commit or does `git reset --hard` and tries something else. Then it does it again. And again. Indefinitely, until you stop it.
Karpathy's original repo is NVIDIA and CUDA only. A developer named trevin-creator ported it to Apple Silicon using MLX, no PyTorch required. It runs natively on the M-series chips, eating unified memory instead of GPU VRAM. Which is why I could run it on a Mac Studio sitting on my desk.
Setup and the surprise baseline
Install took about three minutes. `uv sync` pulled MLX and six other small dependencies. `uv run prepare.py` downloaded eleven training shards from the public HuggingFace dataset and trained a BPE tokenizer in 41 seconds.
Then I did one manual run, as the setup instructions said to: a single 5-minute training experiment to establish a hardware baseline, no modifications.
The first surprise: `val_bpb 1.563`. The public README documents a manual walk on older Apple Silicon that bottomed out at `1.807` after four experiments. My first run, before the AI agent had done anything, was already 13% better than that published best. I didn't tune anything. I pulled the repo and ran it.
The reason is in how the loop is constructed. The training budget is fixed at 5 minutes of wall clock. The M3 Ultra throughput is high enough that it fits 555 optimizer steps into that window, while the older hardware fits fewer. Same code. Different step count. Different result.
The hardware is a parameter, not a constant.
Specs for replication
- Hardware: Mac Studio M3 Ultra, 128 GB unified memory
- OS and runtime: macOS 15, Python 3.12, `uv` 0.10
- Framework: MLX 0.31 with Metal backend (no PyTorch, no CUDA)
- Agent runner: Claude Code (Anthropic)
- Fork used: `github.com/trevin-creator/autoresearch-mlx`
- Per-experiment budget: 5 minutes training, ~90 seconds compile and eval overhead
- Peak unified memory during training: 21.2 GB
Launching the agent overnight
Here's where you have to decide. Karpathy's default advice is to "disable all permissions" and let the agent go. That's the fastest path and it works. But it's also a permission-free Claude Code session running unattended on your Mac for eight hours, with the ability to execute arbitrary shell commands. If the agent hallucinates a destructive action at 3 AM, you won't be there to interrupt it.
I went with a scoped allowlist instead. A `.claude/settings.local.json` file listing exactly the commands the loop actually needs: `uv run train.py`, `git add train.py`, `git commit`, `git reset --hard`, `grep`, `tail`, a few others. Everything else prompts. The agent can't `rm`, can't `git push`, can't install packages, can't touch any file outside the repo.
Then I pointed a fresh Claude Code session at `program.md`, pasted "start the experimentation loop, don't stop," and went to bed.
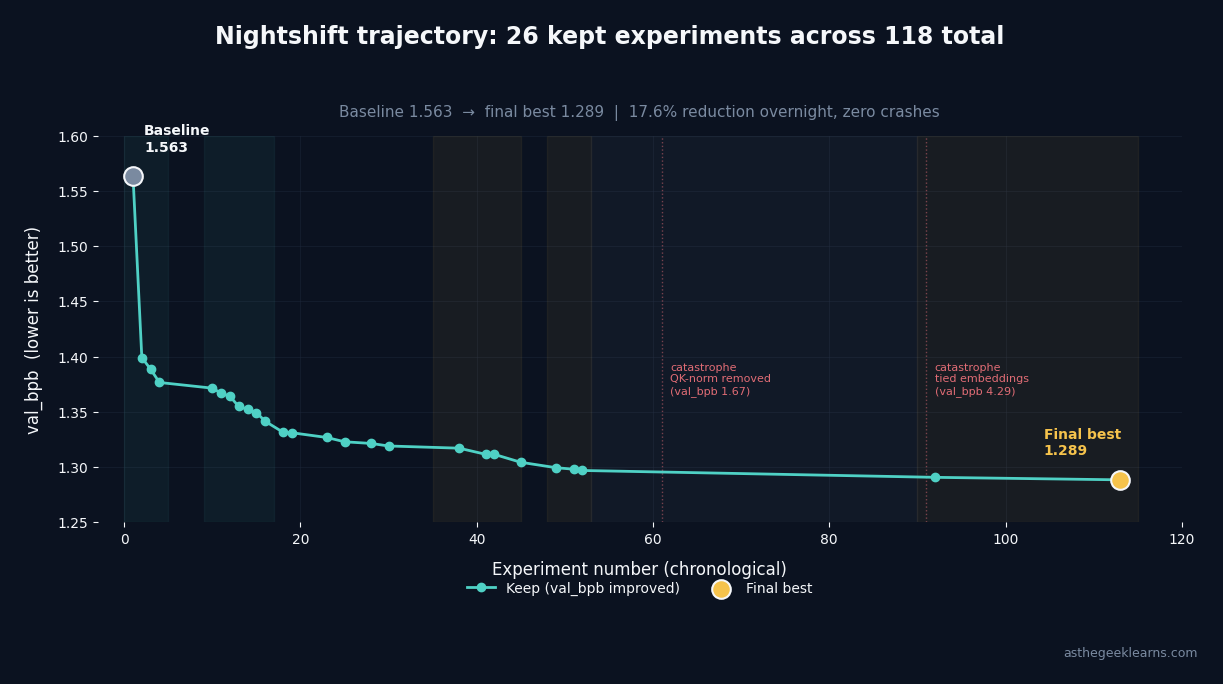
The morning, by the numbers
The morning log:
Comparison to the three overnight runs documented in the public README:
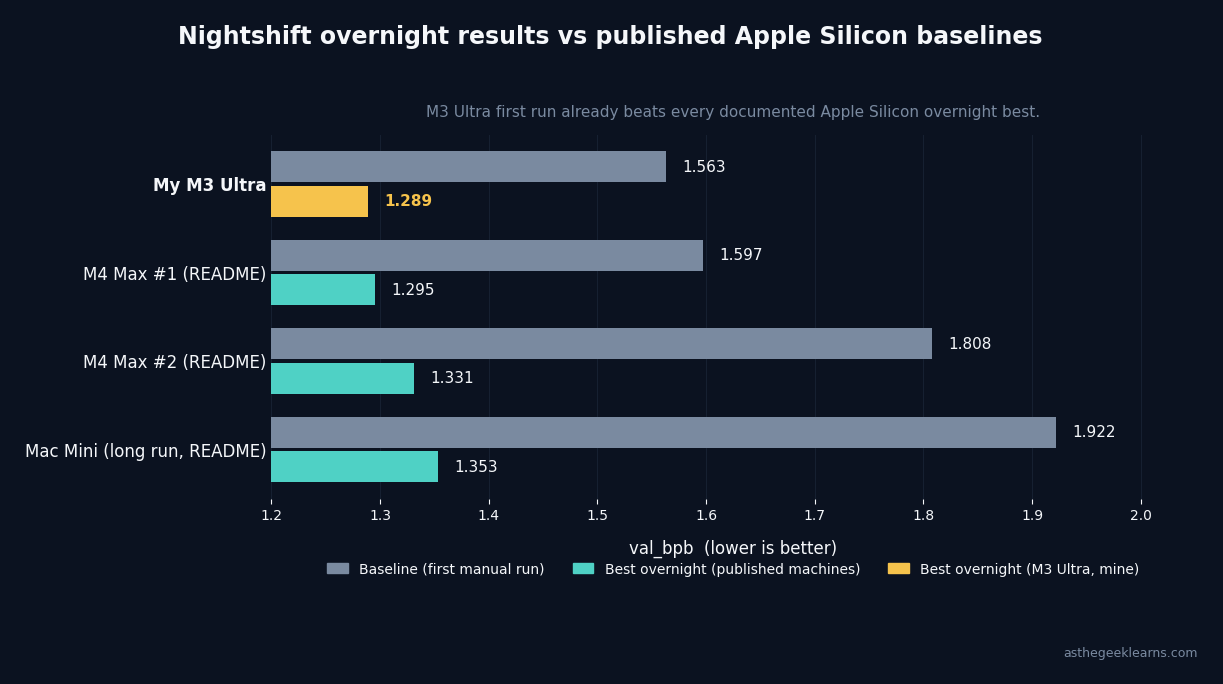
Final `val_bpb` of 1.289 lands below the best documented Apple Silicon overnight result. New territory for the public log.
What the agent actually did
Five phases overnight. Each tells you something.
Phase one: find the big axis. Four experiments in, the agent had halved the batch size three times (1.56, 1.40, 1.39, 1.38), then tried a fourth halving that bounced back to 1.44. The annotation on the discard: "gradient noise." Correct diagnosis. Below a threshold, batch becomes too small for the optimizer to converge inside 5 minutes.
Phase two: schedule tuning, six keeps in a row. The learning-rate schedule was undertuned. The agent walked `WARMDOWN_RATIO` from 0.7 to 1.0, then `WARMUP_RATIO` from 0.02 to 0.2. Every step dropped `val_bpb`. Floor went from 1.38 to 1.34. Biggest easy win of the night, and it was entirely in the schedule.
Phase three: the moment that mattered most. After schedule tuning, the agent retried `TOTAL_BATCH_SIZE = 2^14`. The same configuration it had rejected in phase one. This time it won.
The agent had discovered the thing most humans miss in hyperparameter tuning: the optimal value of one knob depends on the values of all the other knobs. You don't find N independent settings; you find a consistent N-tuple. The only way to find it is to retry earlier-rejected values after each structural change. I've watched human researchers lock in early wins and never revisit them. The agent didn't. It revisited `EMBEDDING_LR` three times over the night, landing at 1.0, then 1.5, then 1.75 across different phases. Each retry, a small win.
Phase four: two structural wins, one line each. `has_ve()` went from alternating-layers-get-Value-Embeddings to all-layers-get-Value-Embeddings, one `return True` replacing a modular-arithmetic expression. `MLP.__call__()` swapped `ReLU²` for `SiLU`, one function call for another. Both character-count-sized changes. Each dropped `val_bpb` by about 0.01.
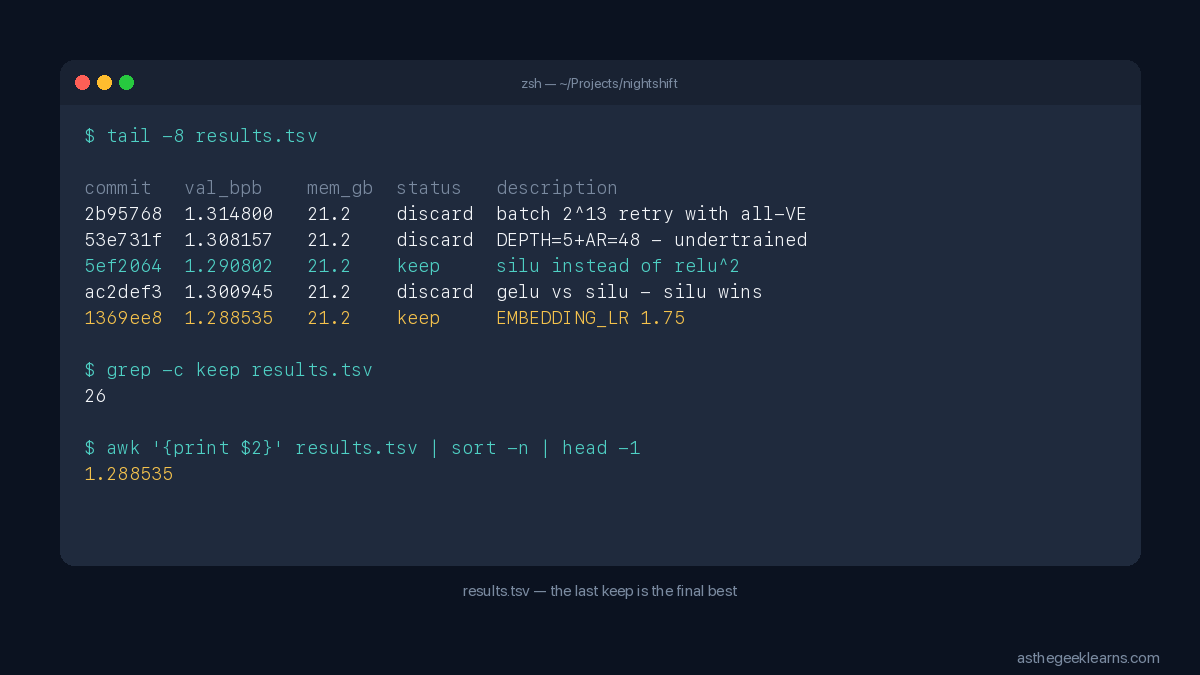
Phase five: the 37-experiment grind. The agent spent 37 consecutive experiments without a single keep, testing every nearby hyperparameter against the current local minimum. Most humans would have quit and tried a wild leap. The agent didn't. It finished the neighborhood, then found the next structural win. Disciplined exhaustion.
And two catastrophes, both correctly reverted. Tied embeddings came back at `val_bpb 4.29`, three times worse than anything else. The agent annotated it "LR mismatch destroys." Tied embeddings is actually a good idea in general, but incompatible with the differential layer-wise learning rates the architecture uses. The agent reverted in seconds. On another experiment, removing QK-norm after RoPE spiked `val_bpb` to 1.67. Annotation: "massive regression." Reverted. A human would have spent an hour trying to salvage tied embeddings. The agent spent ten seconds on the revert. The revert discipline is the whole game.
What it taught me
Two things crystallized overnight.
Disciplined exhaustion beats creative leaps. Humans get bored. After a few hours on the same hyperparameter axis, we start reaching for something new because the exploration stops feeling productive. The agent doesn't have that pressure. It spent 37 experiments without a win because that's what the local search called for, and then it found the next jump. Most humans couldn't do that. Not because we lack the ability, but because we lack the emotional neutrality. The agent's advantage isn't intelligence. It's the absence of boredom, ego, and social pressure. That isn't a 20× productivity gap. It's a categorical one.
Generation is cheap, evaluation is sacred. Every one of the agent's wins was a one-line diff. So was every catastrophe. The "research" wasn't in writing the code. The research was in the metric's ability to rank one-line diffs instantly and unambiguously. Karpathy's genius isn't the agent. It's `val_bpb` plus a 5-minute budget plus `git reset --hard`. That design slots the agent into exactly what AI is magnitudes better at (generating variants, executing at volume) and leaves the hard part (what to measure) to the human who built the loop.
The loop runs on me too
Here's the thing I can't stop thinking about. The loop the agent ran overnight is structurally identical to the one I'm building for my Stoic practice on the same machine.
Morning intention. Five-minute run. Evening review. Keep or discard. Iterate.
Marcus Aurelius wasn't optimizing `val_bpb`. He was optimizing a harder metric with no closed form. But the shape of the loop is the same. Karpathy designed an overnight research org. Epictetus designed an overnight self. Both are the same thing running in different mediums.
The 118-experiment loop ran on a machine on my desk. The second loop runs on me.

If you have a Mac Studio and a spare evening, the repo is at `github.com/trevin-creator/autoresearch-mlx`. Clone it, run `prepare.py`, point a Claude Code session at `program.md`, go to sleep. You wake up to a log of experiments and a better model. And if you're anything like me, you also wake up thinking about which of your own loops could run this way.
A Quick AI Glossary For This Article
Because not everyone speaks ML fluently, here’s a plain-English guide to the terms in this post. I’m still learning too, so these are “practitioner” definitions—enough to follow what’s happening, not academic deep-dives.
The Big Picture
GPT. A type of language model. Stands for “Generative Pre-trained Transformer.” In this article I’m training a tiny one from scratch, not using the big ones like ChatGPT. Same architecture family, just much smaller.
Pre-training. The step where a model learns to predict the next word (or “token”) across a huge pile of text. This is what `train.py` is doing. It happens before any of the fine-tuning that turns a base model into a chatbot.
val_bpb (validation bits per byte). The score the agent is optimizing. Lower is better. It’s a measure of how surprised the model is by held-out text it hasn’t seen during training. A model that predicts well has low surprise. Bits per byte is a way of measuring that surprise that works across different tokenizers, so you can compare different architectures fairly.
Loss metric. Any number that tells you how wrong a model is on a given task. Training is the process of making that number go down. `val_bpb` is a loss metric.
The Stack
Apple Silicon. Apple’s own CPU/GPU chip family (M1, M2, M3, M4). Uses unified memory, which means the CPU and GPU share the same pool of RAM instead of having separate memory pools. For AI workloads this is a big deal because you don’t have to copy data between CPU RAM and GPU VRAM.
MLX. Apple’s open-source machine learning framework, built specifically for Apple Silicon. Think of it as Apple’s answer to PyTorch but native to Metal (Apple’s GPU API). No PyTorch, no CUDA, no NVIDIA drivers needed.
PyTorch. The dominant open-source ML framework. Most research code you see online assumes PyTorch. It runs on NVIDIA GPUs (via CUDA) and, with caveats, on Apple GPUs (via MPS). MLX is an alternative that sidesteps PyTorch entirely.
CUDA. NVIDIA’s API for running general-purpose compute on their GPUs. If you’ve ever seen a blog post say “requires a CUDA-capable GPU,” they mean an NVIDIA card.
GPU VRAM. The memory that lives on a GPU card, is separate from your computer’s main RAM. On Apple Silicon, VRAM and main RAM are the same pool (that’s the “unified memory” thing).
Tokenization & Data
Tokenizer. The thing that turns text into numbers the model can actually work with. “Hello world” might become `[15496, 995]`. The model only ever sees the numbers.
BPE (Byte-Pair Encoding). The most common algorithm for building a tokenizer. It starts with individual characters and iteratively merges the most common pairs until you have a vocabulary of “tokens” that balance common words (one token) and rare words (split into pieces).
Shards. Chunks of a large dataset, split into files for parallel download and loading. Our setup uses 11 shards from a public text dataset.
Training Mechanics
Optimizer. The algorithm that actually updates the model’s weights during training. AdamW is the one used here. Every “optimizer step” is one update.
Batch size. How many training examples the model looks at before making one weight update. Bigger batches give smoother gradient estimates but use more memory. Smaller batches fit more weight updates into a fixed time budget.
Gradient accumulation. A trick for getting large effective batch sizes on limited hardware. Process smaller mini-batches sequentially, add up their gradients, then apply one update. `TOTAL_BATCH_SIZE / DEVICE_BATCH_SIZE` tells you how many mini-batches per update.
Gradient noise. When your batch is so small that the gradient estimate becomes statistically unreliable. The optimizer starts jerking around instead of smoothly descending, and training slows or stalls. The agent correctly identified this as the failure mode at batch 2^12.
Learning rate (LR). How big a step the optimizer takes each update. Too high, and training blows up. Too low, and it barely progresses. The sweet spot depends on everything else.
Learning rate schedule. How the learning rate changes over time. Typically: warm up from zero to peak, cruise, then warm down to zero. `WARMUP_RATIO = 0.3` means the first 30% of training is the warm-up.
Differential / layer-wise learning rates. Using different learning rates for different parts of the model. In the nightshift setup, the embedding layer gets LR 1.75, but the output projection (`lm_head`) gets 0.006 — a 290× difference. This matters because different parameter types have very different sensitivities.
Architecture Pieces
Attention (or attention layer). The core mechanism that lets a transformer model “pay attention to” relevant earlier tokens when predicting the next one. Modern LLMs are mostly stacks of attention layers alternating with MLPs.
MLP (multi-layer perceptron). A simple feed-forward neural network with one or two hidden layers. In a transformer, an MLP sits between each pair of attention layers and does the “thinking” on the representations attention produced.
Activation function. A nonlinear function applied inside a neural net. Without activations, no matter how many layers you stack, the whole thing collapses mathematically into one linear transformation. Examples in this article: `ReLU²` and `SiLU`.
SiLU (Sigmoid Linear Unit). `x * sigmoid(x)`. A smooth, differentiable activation function. Also called Swish. Used in many modern models because it plays nicely with optimizers.
ReLU² (squared ReLU). `max(x, 0) ** 2`. The piece that nanoGPT-speedrun and some research codebases use. Produces sparse, squared activations. Theoretically expressive but less numerically stable than SiLU for short training runs — which is why SiLU won overnight.
Embedding. The lookup table that converts each input token (a number) into a vector of real numbers. The model learns what each vector should be during training. `wte` = word token embedding.
Value Embeddings (VE). An additional set of embeddings injected into attention layers as the “value” vectors. Think of them as a skip connection from the raw input that every attention layer can consult, on top of what the previous layer produced. Helps information flow when the network is deep.
Tied embeddings. Sharing the input embedding weights with the output projection weights (the thing that produces final logits). Saves millions of parameters. Commonly used in GPT-2 and many others. Broke catastrophically in our run because the differential learning rate setup couldn’t handle the shared weight.
QK-norm (Query-Key normalization). A stabilization trick: normalize the query and key vectors inside attention before computing attention scores. Without it, score magnitudes can spike, saturating the softmax. The agent tried removing QK-norm and `val_bpb` jumped 28% worse.
RoPE (Rotary Position Embedding). How the model knows the order of tokens. Rotates the query and key vectors by an angle that depends on the token’s position. Standard in modern transformers.
Softmax. The function that turns raw attention scores into a probability distribution over the tokens you might attend to. Highly peaked inputs cause “softmax saturation” — most of the weight collapses onto one token and gradients downstream get weak. That’s why QK-norm matters.
Methodology
Hyperparameter. Any configuration value you set *before* training, as opposed to weights the model learns *during* training. Batch size, learning rate, WARMUP_RATIO, depth—all hyperparameters.
Hyperparameter tuning. The art (and mostly the grind) of finding good hyperparameter values. Most of what the agent did overnight was hyperparameter tuning.
Interaction effect. When the optimal value of hyperparameter A changes depending on what hyperparameter B is set to. A consistent set of hyperparameters is not N independent optima — it’s one N-tuple.
Local search. A research strategy: after finding an improvement, test every nearby variation of your current best before venturing somewhere completely different. Tedious for humans. Perfect for agents that don’t get bored.
If I missed a term you’d have liked defined, please let me know in the comments and I’ll add it.